One of the most frequent questions I get while running aickyway is "What does it actually mean when AI understands images?" If you've ever thrown a screenshot at Gemini and asked about an error, you know it doesn't just magically work. There's quite a complex architecture running behind the scenes.
I recently came across a blog post on QuarkAndCode that neatly covered this topic from architecture to deployment (original: "Multimodal LLMs Guide: Text, Image & Video, RAG Search & vLLM", 2024.12.31). I took some notes while reading, and I'll try to break it down based on what I know. The training theory section leans heavily on the original article since I've never implemented the papers myself, while the serving and RAG sections will be longer since I have hands-on experience with those.

Quick Terminology
There are many English abbreviations throughout the article, so let me define them once here to keep things concise.
Modality — A type of data. Text, images, video, and audio are each a modality. A multimodal model processes two or more of these simultaneously.
Embedding — Data converted into numerical vectors that AI can compute with. Similar meanings are positioned close together in vector space.
VQA (Visual Question Answering) — A task where the model answers questions about an image.
RAG (Retrieval-Augmented Generation) — An approach where relevant materials are retrieved before generating an answer.
The rest will be explained when they first appear in the text.
Internal Architecture of Multimodal LLMs
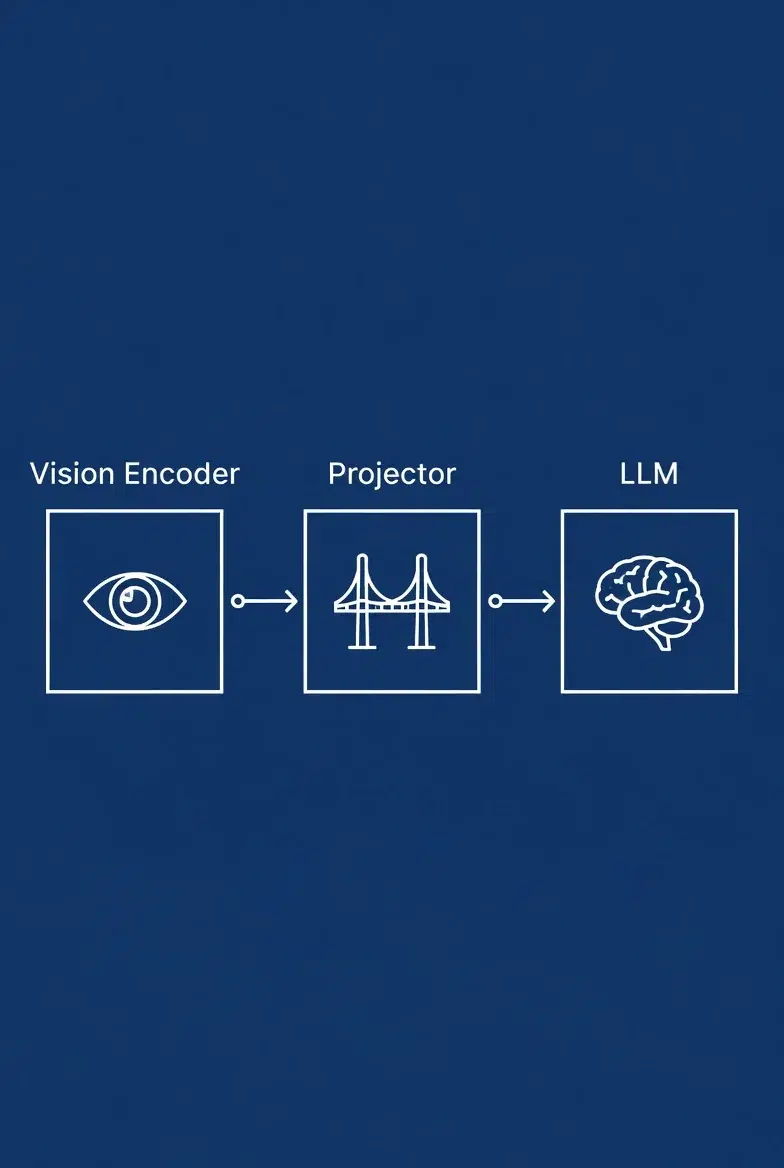
To cut to the chase, the architecture itself is simple. Vision Encoder → Projector → LLM. Three blocks.
The vision encoder converts an image into feature vectors, the projector transforms those vectors into token formats the LLM can digest, and the LLM combines them with text tokens for inference.
The projector is surprisingly important here, and LLaVA is a good example. The original LLaVA (v1) used a simple single linear layer as its projector. When LLaVA-1.5 switched to a 2-layer MLP (Multi-Layer Perceptron), benchmark scores improved significantly. How well the projector "translates" image features into the language model's token space directly affects overall performance. In many cases, improving the projector is more cost-effective than changing the vision encoder itself.
Vision encoders typically use the ViT (Vision Transformer) family, splitting images into 14×14 or 16×16 pixel patches and treating each patch as a token. A 224×224 image split into 16×16 patches produces 196 tokens, and this number grows rapidly as resolution increases. This is exactly why Qwen2-VL supports dynamic resolution.
Architecture Types — Retrieval vs. Generation
There are multiple design approaches, but from a practical standpoint, there's one key distinction.
For retrieval/matching purposes, use Two-Tower. Images and text are processed by separate encoders, and output vectors are compared in the same space. CLIP is the prime example, optimized for determining "how semantically close are this image and this text." Strong for image search and similarity matching.
For reasoning/generation purposes, use Encoder-Decoder. The encoder processes the image, and the decoder generates answers through cross-attention (a mechanism that references image features during text generation). Suitable for VQA, captioning, and instruction-following tasks.
There are variants that insert fusion layers in between, or architectures that separate text into context comprehension and generation, but most commercial models are close to one of these two branches. The other variants can be looked up when needed.
Training Methodologies
This section is based on the original article and papers rather than my own implementation experience.
There are four main ways multimodal models learn the "relationship between images and text."
Contrastive Learning — The method used by CLIP. Matching image-text pairs are trained to be close in embedding space, while mismatched pairs are pushed apart. The loss function uses InfoNCE loss, which maximizes the similarity of correct pairs among all image-text combinations within a batch. Larger batch sizes (= more comparison targets) lead to better training, which is why the original CLIP paper used a batch size of 32,768. Reproducing this number as an individual is practically impossible, which is why most people use pre-trained CLIP weights.
Masked Modeling — An extension of BERT's text word masking to image regions. The model learns cross-modal relationships by reconstructing masked portions.
VQA Pre-training — Direct training with question-answer pairs about images. Focused on building reasoning ability rather than matching.
Instruction Tuning — The fine-tuning stage where the model learns to follow user instructions like "summarize this chart" or "find something unusual in the photo." Without this process, the model can only do basic captioning and cannot function as an interactive assistant.
One note about training data scale: Qwen2-VL used billions of image-text tokens, and this level of computing cost is beyond what individuals or small teams can afford. This is why "using" multimodal models rather than "building" them is the realistic choice.
Video Is a Different Problem
I'll keep this section brief. I have no hands-on experience with video multimodal, so I'll just convey the main points from the original article.
An image is a single snapshot, while video adds a temporal dimension. At 30fps, one minute equals 1,800 frames, and since processing all of them is impossible, a key frame extraction strategy is needed, along with solving the temporal misalignment problem between narration and scenes.
Currently, text+image multimodal is already at commercial quality with Gemini and GPT-4o, but the original article's assessment — and I agree — is that most video understanding models are still closer to the research stage.
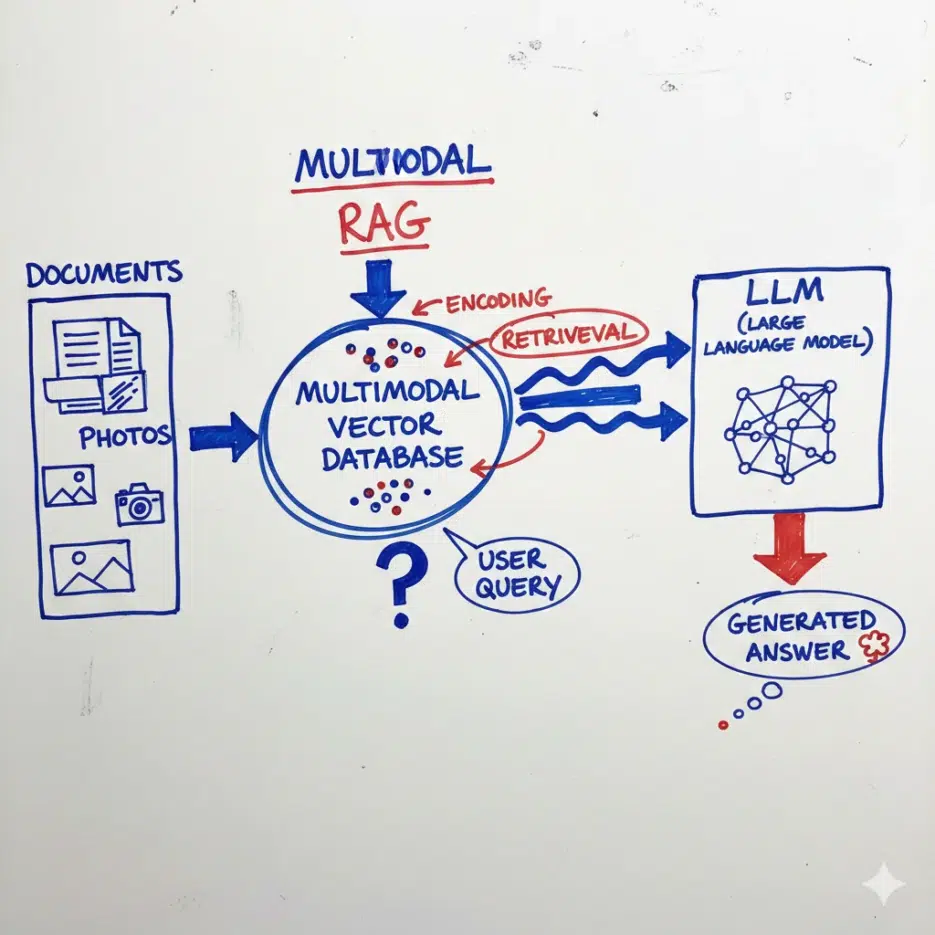
Multimodal RAG — This Is Where the Real Money Is
This section will be the longest, and for good reason. We're evaluating a feature for aickyway's next update that would automatically link related technical documents to user-uploaded images, and I did a deep dive into multimodal RAG during that process.
RAG itself is "an approach where AI searches for and references relevant materials before generating an answer." Instead of cramming all knowledge into model parameters, it retrieves necessary evidence from external sources at inference time. Multimodal RAG extends the search targets beyond text to include images, diagrams, and video frames.
Practical Use Cases
I'll keep this brief. Here are the areas where multimodal LLMs actually work in practice right now:
Automatic document, form, and table interpretation — This has the biggest impact. There used to be a pipeline of extracting text with OCR (technology for extracting characters from images) → parsing with regex, and anyone who's used Korean OCR knows how terrible the accuracy is. Multimodal models can interpret receipt or form images directly when fed whole. Considering the time spent post-processing broken OCR results, the productivity difference is significant.
VQA and visual reasoning — Chart analysis, diagram interpretation, identifying object relationships in images. If you've used Gemini Pro Vision or GPT-4o, you've already experienced this.
Industrial applications — Combining medical imaging with patient records for diagnostic assistance, automatic defect classification on manufacturing lines, etc. However, accuracy requirements are high in these areas, so standalone use without human review is still rare.
Deployment — This Is Where I Struggled the Most
I'm running the aickyway backend on a single RTX 4090 24GB GPU server, and here's what I experienced while testing multimodal model serving.
When I first loaded LLaVA-1.5 7B, text-only inference was stable at around 14GB VRAM. But once I started feeding images, each image added 576 tokens from the vision encoder output, and with just 2-3 concurrent requests, VRAM hit 24GB and OOM (Out of Memory) crashed everything. Lowering image resolution helps to some extent, but then fine-grained recognition quality drops, defeating the purpose.
Batching was also a problem. Text-only models have relatively uniform input lengths, making batching straightforward, but multimodal requests have extreme token count variations depending on whether images are included. When an image-free request (200 tokens) and a 3-image request (2,000+ tokens) end up in the same batch, the short request has to wait until the long one finishes. Naive static batching simply cannot solve this problem.
That's when we adopted vLLM, and the difference was clear.
What Exactly Does vLLM Solve?
vLLM is an open-source LLM inference engine from UC Berkeley's Sky Computing Lab. It has several key technologies that directly address the problems described above.
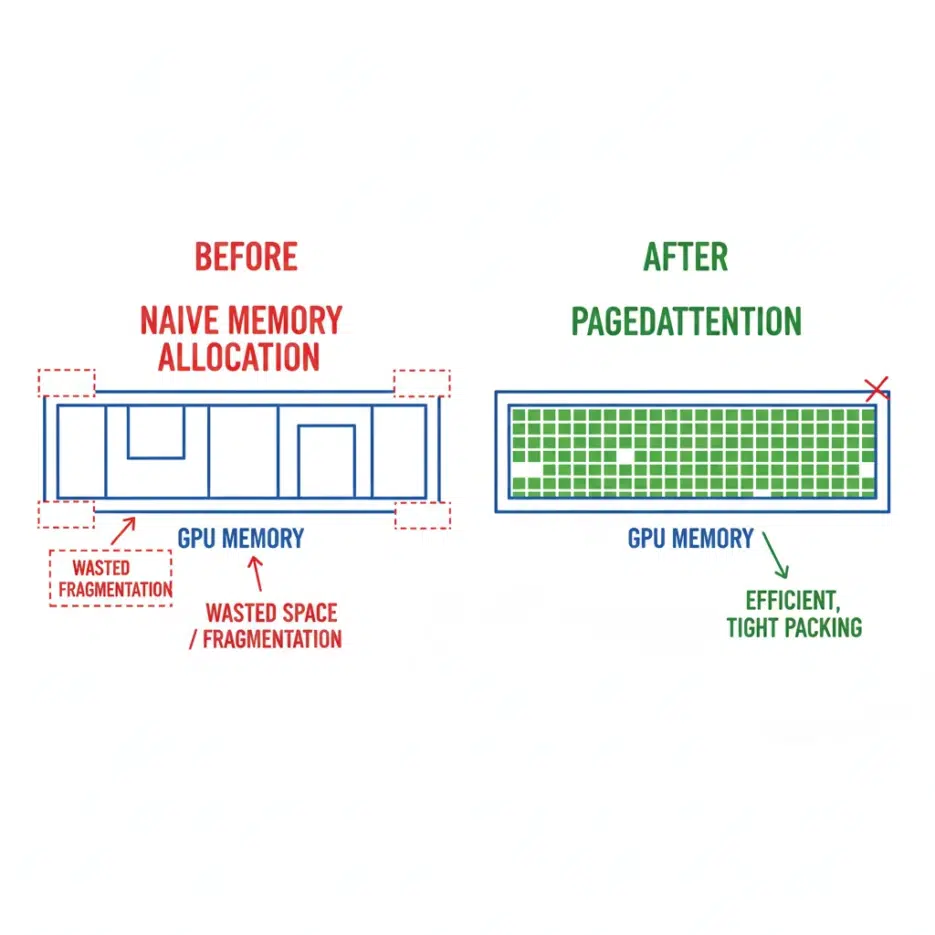
PagedAttention — The core solution for VRAM OOM issues. The biggest memory consumer in LLM inference is the KV cache (memory storing attention keys/values from previous tokens), and the conventional approach pre-allocates memory for the maximum sequence length. This means even a 100-token request consumes memory for 2,048 tokens. PagedAttention allocates memory in page units (typically 16 tokens) on demand, similar to OS virtual memory. The original paper reported up to 97% reduction in memory waste, and in practice, the number of concurrent requests that could be handled on the same GPU roughly doubled or tripled.