I Got an Error Training Vertical Images, So I Looked Into How SD Handles Resolution
Useful Terms to Know First
| Term | Description |
|---|---|
| Tensor | A multi-dimensional array. It's an image converted into a blob of numbers that computers understand. It's stored in height×width×color channels format. |
| Batch | A group of images processed together at once. If you bundle 4 images, batch size = 4. |
| VAE | Variational AutoEncoder. An encoder that compresses images into a small "latent space." |
| UNet | The core neural network that generates images by removing noise. It's called UNet because it's U-shaped. |
| Aspect Ratio | Width:height ratio. 1:1 is square, 16:9 is widescreen, 9:16 is portrait. |
| DiT | Diffusion Transformer. A modern architecture that uses transformers instead of the traditional UNet. |
Stable Diffusion trains on images of truly diverse resolutions. Tall portrait photos, wide landscape photos, full-body illustrations. But here's where a question arises.
🚨 PyTorch Constraint: If you put tensors of different sizes in the same batch, you get an error.
RuntimeError: expected all tensors to be of the same size
Trying to bundle a 512×512 image with a 1024×512 image? Instant error. This isn't a bug—it's a fundamental constraint. Tensor operations need uniform dimensions to efficiently calculate gradients.
So how does Stable Diffusion handle diverse resolutions? The answer lies not in the model itself, but in the data pipeline. It's a technique called Aspect Ratio Bucketing.

📦 PyTorch Batch's Iron Rule: Sizes Must Be Identical
A PyTorch batch is a tightly-packed tensor. All elements must have identical spatial dimensions. When you call torch.stack(), the system verifies that all tensors have the same height, width, and number of channels.
A 512×512 image and a 1024×512 image cannot be stacked. Latent representations after VAE downsampling (64×64 and 128×64) must also have matching shapes. UNet relies on consistent tensor dimensions to apply kernels across the entire batch and compute attention in parallel.
💡 Key Point: This isn't a limitation you can bypass with padding or resizing. The model never sees original images of different sizes in the same batch. It only sees batches of latent vectors with identical dimensions. Variability is managed before data enters the model—by the data loader, not the architecture.
🪣 Aspect Ratio Bucketing: The Core Solution
The solution is simple and clear: group images by aspect ratio, then sample batches only from within those groups.
All training images are sorted into buckets containing images with identical resolution:
- Bucket 1: All 512×512 images
- Bucket 2: All 1024×512 images
- Bucket 3: All 512×1024 images
- Bucket 4: All 768×512 images
- ... and so on
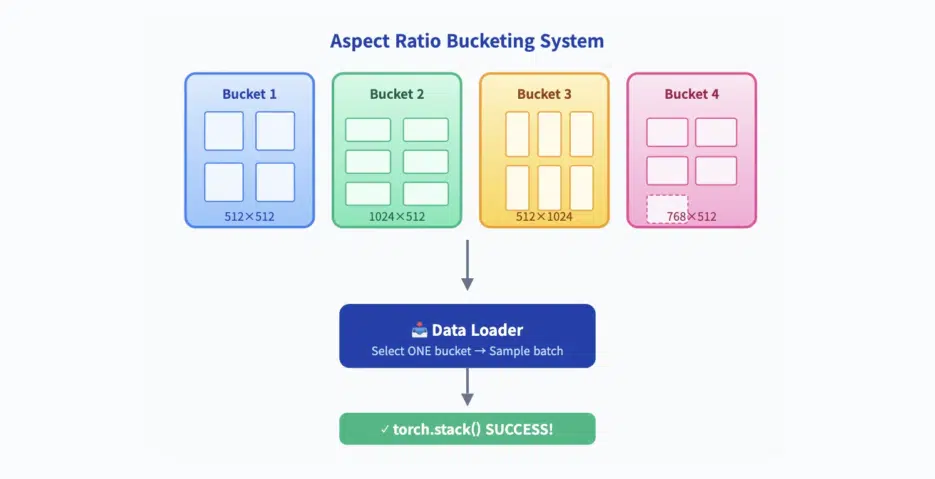
During training, the data loader randomly selects one bucket and fetches an entire batch (e.g., 4 images) from that bucket. Since all images in the batch have identical dimensions, torch.stack() succeeds, VAE encodes them into matching-shaped latent vectors, and UNet processes without errors.
📌 This isn't optional. Without bucketing, training non-square images in PyTorch is impossible. It's the standard method used by all major training tools: Kohya_ss, NovelAI, Diffusers, SDXL fine-tuning scripts, and more.
Buckets aren't selected arbitrarily. Too few buckets limits resolution diversity; too many risks each group being undersampled, leading to unstable training. The goal is to cover the most common aspect ratios while maintaining sufficient batch size for stable gradient updates.
SDXL's Pixel Budget and VAE Downsampling Constraints
SDXL introduced a key improvement: a target pixel budget of approximately 1024² pixels (about 1,048,576 pixels) per image. For a given aspect ratio, the system selects the closest resolution that satisfies three conditions:
- Total pixel count is close to 1024²
- Both width and height are divisible by 64 (because VAE downsamples by 8x)
- The original aspect ratio is preserved as much as possible

For example, for a 3:2 image, the system doesn't use 1536×1024 (1.5 million pixels). Instead, it uses 1216×832. Both dimensions divide cleanly by 64:
- 1216 ÷ 64 = 19 ✓
- 832 ÷ 64 = 13 ✓
- Resulting latent vector: 152×104
This design ensures all latent vectors in a batch have identical shapes. If VAE downscaled by 7 or 9, integer division would fail and bucketing wouldn't work. The latent space is designed to make this process possible.
✂️ Early Cropping vs Modern Bucketing
Before bucketing, the only option was to resize or crop all images to 512×512. In SD1.x and SD2.x, a 2000×1000 image was cropped to fit.
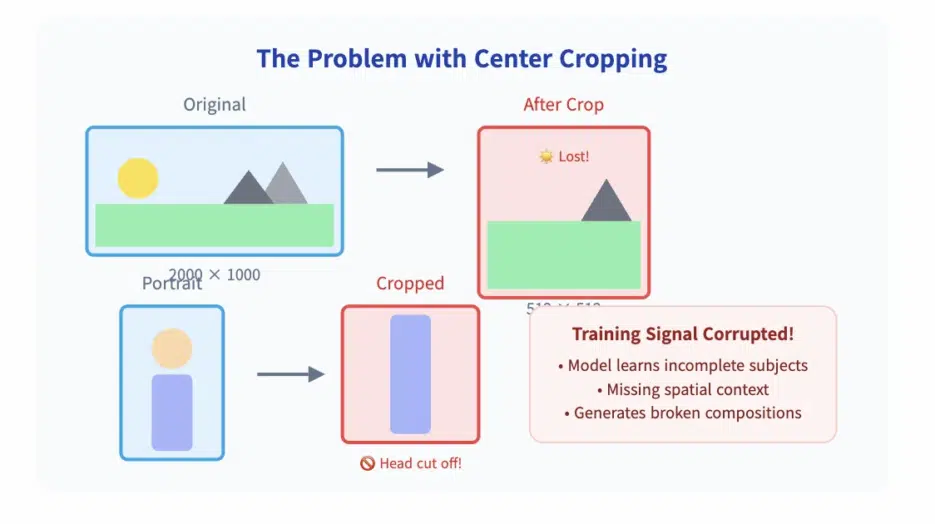
Tall images lost their top or bottom, wide images lost their sides. Portrait photos ended up with heads cut off, landscapes lost their horizons, and buildings were sliced in half.
This wasn't just a visual flaw. It contaminated the training signal. Since the model saw incomplete subjects, it learned to predict incomplete subjects. Instead of learning complete anatomy or spatial context—it learned to fill in missing parts.
Bucketing changed this. By preserving original composition and scaling images to fit natural aspect ratios, models learned to generate consistent, complete-content images at any resolution. This wasn't a minor improvement. It became the foundation for SDXL's superior performance on non-square images.
DiT Architecture and Variable-Length Sequences
Modern architectures like DiT (Diffusion Transformer) can handle variable-length sequences during inference. DiT uses 2D RoPE (Rotary Position Embedding) to encode spatial positions, allowing the model to interpret a 128×64 latent grid differently from a 152×104 grid.
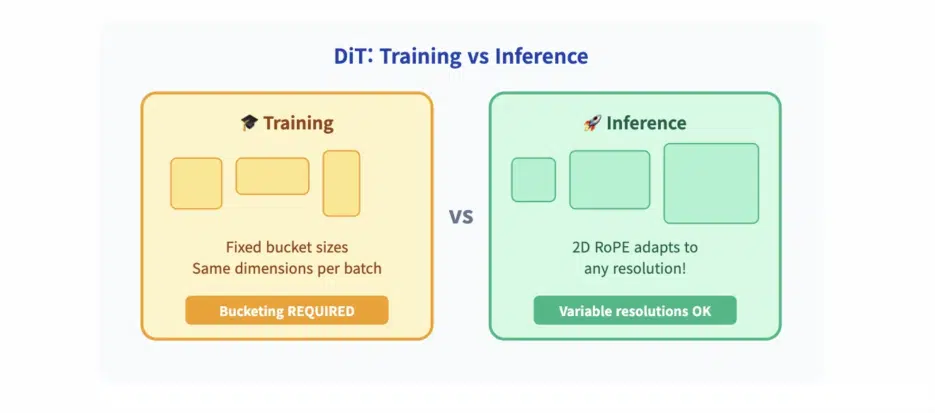
This enables high-resolution generation—even if the model was only trained on 1024×512 and 512×512 buckets, it can generate 2048×1024 images. 2D RoPE adapts to the new token count during inference.
⚠️ But this flexibility doesn't extend to training. Even DiT-based models like Hunyuan-DiT or Wan still use bucketing during training. Why? Because gradient computation, attention caching, and memory alignment require uniform batch shapes.
Models can infer at variable resolutions, but must train at fixed resolutions. Bucketing remains an engineering reality of training. Variable-length sequences are an inference feature, not a replacement for batch consistency.
Conclusion: Don't Ignore Bucketing
Stable Diffusion cannot train on images of different sizes in the same batch. PyTorch requires identical tensor dimensions. The solution is aspect ratio bucketing: grouping images by resolution and sampling batches only from within those groups.






