PokeFusion Attention: Enhancing Reference-Free Style-Conditioned Generation Paper Review
PokeFusion Attention: Enhancing Reference-Free Style-Conditioned Generation
Review by aickyway · Original: Jingbang (James) Tang (2026)
If you've ever used AI image generation models, you've probably encountered this frustration: "I want to keep the character's form while only changing the style in detail, but why does the character's face keep changing or the style mix up strangely?"
Traditional methods relied solely on text prompts or required connecting complex external images as reference models. However, text alone couldn't perfectly describe visual styles, and external reference methods consumed too many computational resources.
The recently published 'PokeFusion Attention' paper solves both character consistency and style precision simultaneously by simply modifying the model's internal 'Attention' mechanism, without any of these complex processes.
The Wall Faced by Traditional Methods: Style Drift and Structural Collapse
The most difficult thing for AI when drawing is expressing 'feelings that cannot be described in words.'
- Limitations of Text (Style Drift): Even when you input "Pikachu in watercolor style," the AI often breaks down Pikachu's unique appearance (structure) while processing the watercolor style. This is called the style drift phenomenon.
- Heaviness of Reference Methods: To solve this, adapter technology that makes the model refer to other images is used, but this complicates the model's structure and slows down generation speed.
PokeFusion Attention creates a new pathway to efficiently inject style information while leaving the model's core backbone untouched.
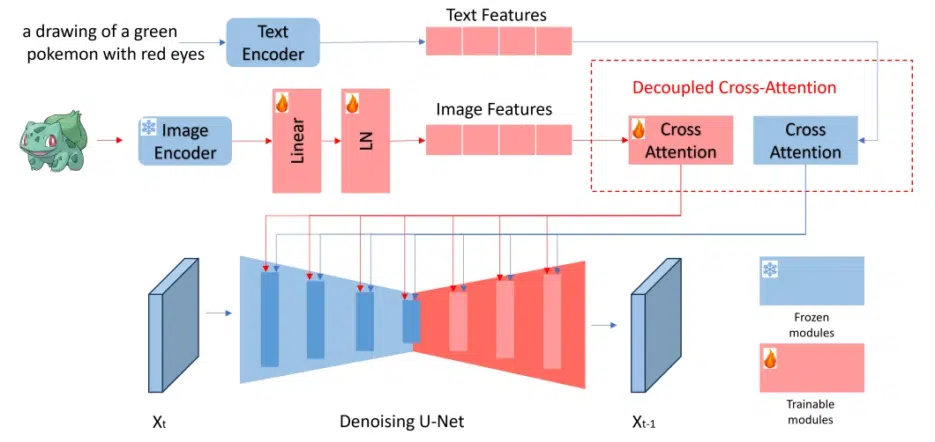
The Core of PokeFusion Attention: Separation of Text and Style
The key idea of this paper is to use 'Decoder-level Cross-Attention' to process text information and style information separately.
1. Freeze the Backbone and Replace Only the Antenna
The existing model's overall intelligence (Backbone) is kept intact (Frozen). Instead, only the 'cross-attention' layers in the final decoder stage of image generation are trained. This is similar to leaving the structure of a house intact while only installing new interior design and lighting controllers.
2. Direct Injection of Style Embeddings
PokeFusion Attention doesn't simply describe styles in words but injects them directly as 'learned style vectors.' This allows text information and style information to perform their respective roles without conflicting. Text handles "what to draw," while PokeFusion fixes "how it should feel."

Understanding PokeFusion Structure for Developers
If we simulate the flow when actually implementing or applying this technology in Python code, it would look something like this:
import torch
import torch.nn as nn
class PokeFusionAttention(nn.Module):
def __init__(self, query_dim, context_dim, style_dim):
super().__init__()
# Projection layers for processing text and style separately
self.to_text_kv = nn.Linear(context_dim, query_dim * 2, bias=False)
self.to_style_kv = nn.Linear(style_dim, query_dim * 2, bias=False)
self.scale = query_dim ** -0.5
def forward(self, x, text_context, style_embedding):
# x: Latent space data of the image being generated
text_kv = .to_text_kv(text_context)
# 2. Extract style information (core of PokeFusion)
style_kv = self.to_style_kv(style_embedding)
# 3. Fuse both information and compare with image data (Query)
# In this process, character structure and style are reflected independently
merged_kv = torch.cat([text_kv, style_kv], dim=1)
# Then perform standard Attention operation...
return output
While traditional methods mixed text and style in a single sentence input, PokeFusion dramatically improves style consistency by injecting `style_embedding` through a separate pathway as shown in the code above.
---
## Efficiency Proven Through Experiments
The paper validated performance through various character and style combinations.
* **Consistency:** Even when different prompts were input multiple times, the character's unique silhouette and features remained unchanged.
* **Parameter-Efficiency:** By training only specific layers and style projection modules instead of the entire model, high-quality style application was possible with significantly fewer computing resources than traditional methods.
* **No Reference Images Required:** Once a style is learned, there's no need to upload separate images to the server during generation, making deployment easy.
---

---
## Implications and Conclusion
PokeFusion Attention is not just technology for drawing pretty pictures, but research that elevates **'Controllable Generation'** to the next level.
It is expected to be particularly powerful in fields where consistency is essential, such as implementing various costumes for game characters or maintaining art styles in webtoons/animations. The biggest appeal of this technology is that it can attach and detach specific styles in a 'plug and play' manner while maintaining the model's main performance.
This paper stood out for its attempt to overcome the uncertainty of text-based generation through technical architectural improvements.
---
**References**
* Tang, J. J., "PokeFusion Attention: Enhancing Reference-Free Style-Conditioned Generation", arXiv:2602.03220, 2026.






