Expert-Data Alignment Governs Generation Quality in Decentralized Diffusion Models
1. Introduction: Why This Paper Caught My Attention
[Editor's Perspective] There's a saying that "two heads are better than one." In machine learning, particularly in ensemble techniques, averaging predictions from multiple models has long been considered the gold standard for improving performance. I, too, have often resorted to "let's just combine several models" when individual model performance fell short.
However, the paper I'm introducing today directly challenges this conventional wisdom. When combining multiple expert models, the results were mathematically more stable, yet the actual generated images turned out to be a mess. With on-device AI and Federated Learning gaining traction recently, 'Decentralized Diffusion Models (DDM)' are receiving significant attention, and this paper strikes at the heart of a critical design dilemma. Let's dive deep into this research that demonstrates why 'focus and selection' becomes increasingly important as AI scales up.
2. What Are Decentralized Diffusion Models (DDM)?
Instead of building one massive AI model, DDM divides data into multiple segments and trains separate smaller models (experts) on each segment. For example, Expert A learns only from 'dog' data, while Expert B learns only from 'car' data. When generating an image, these experts are called upon to contribute to the creation.
This raises a crucial question: "When drawing a picture, who should we call?"
- Full Ensemble: Listen to all experts A, B, C... and average their opinions.
- Sparse Routing (Top-k): Call only 1-2 experts most relevant to the current image being drawn.
Intuitively, option 1 seems more stable, but the paper's findings are shocking.
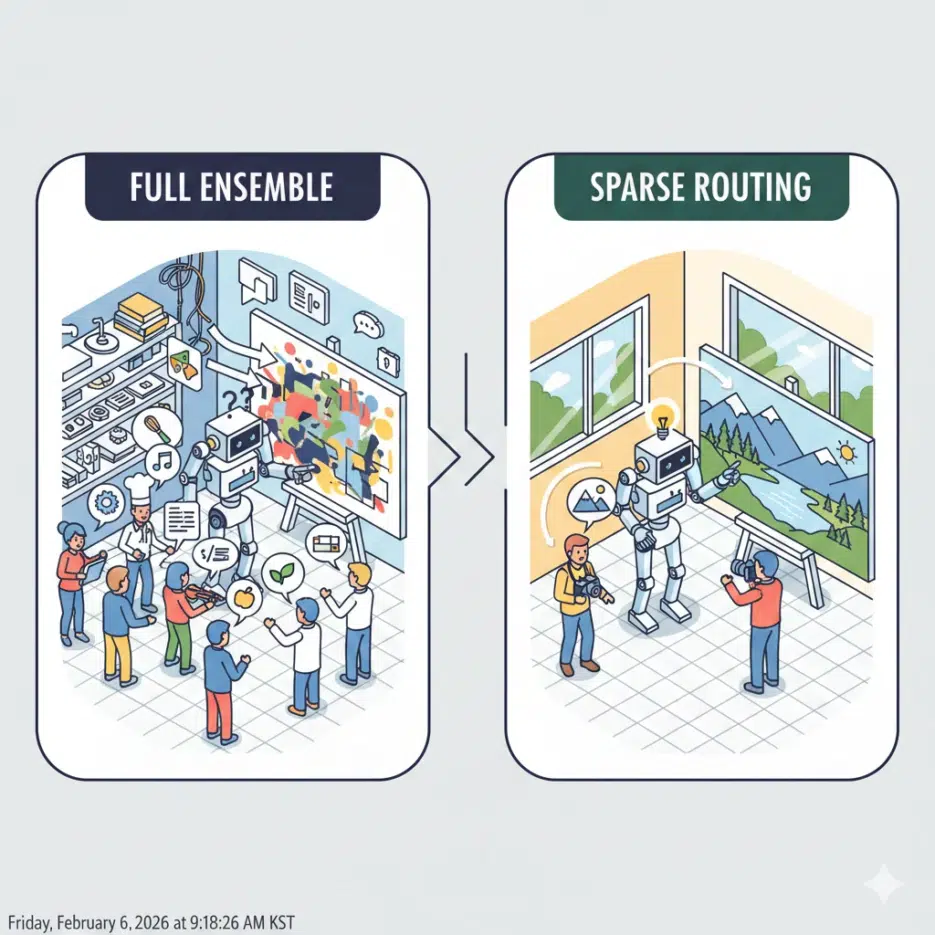
3. Key Discovery: Stability-Quality Dissociation
The researchers discovered a phenomenon called 'Stability-Quality Dissociation' through their experiments.
- Mathematical Stability: The Full Ensemble (involving all experts) was numerically the most stable. (Lower Lipschitz constant)
- Visual Quality: However, image quality (FID score) was the worst. Conversely, involving only 1-2 experts (Top-k) produced overwhelmingly better image quality.
Why Does This Happen? (Expert-Data Alignment)
The reason lies in 'Expert-Data Alignment'. When you're drawing a dog and the 'car expert' intervenes, the car expert says "this noise looks like a wheel" and guides the image toward wheels. The dog expert will insist "no, it's fur." These conflicting opinions (gradients) cancel each other out, resulting in an indeterminate gray blob (Average Grey).
Ultimately, the core conclusion is that high-quality images can only be generated when work is delegated to "experts who have actually learned from the relevant data."
4. [Key Terms Explained] Concept Guide for Beginners
Here are the difficult terms you need to understand to grasp this paper, explained simply.
- DDM (Decentralized Diffusion Models): An AI model architecture where data is distributed across multiple locations, trained separately, and then combined for use later. This is advantageous for privacy protection.
- Routing: The rule that determines "who should we ask at this step?" 'Top-k' means asking only the top k experts, while 'Full' means asking everyone.
- Manifold: Think of it as 'the space where data makes sense.' For example, random noise exists outside the manifold, while real dog photos exist on the manifold. Experts work to pull noise onto the manifold.
- FID (Fréchet Inception Distance): A scoring system that measures how similar AI-generated images are to real photos. The lower the score (closer distance), the better the generation.
5. Implementation Guide for Developers (Python Simulation)
I've created pseudo-code to help understand how the 'routing strategy' central to this paper differs at the code level.
import torch
class DecentralizedDiffusion:
def __init__(self, experts):
self.experts = experts # List of multiple small U-Net models
def predict_noise(self, x_t, t, strategy='top_k', k=2):
"""
x_t: Current noisy image
t: Timestep
strategy: 'full' or 'top_k'
"""
predictions = []
# Calculate predictions for each expert
for expert in self.experts:
pred = expert(x_t, t)
predictions.append(pred)
predictions = torch.stack(predictions)
if strategy == 'full':
# [BAD Quality] Average all experts' opinions
# Car expert interferes with dog image -> blurry result
final_pred = torch.mean(predictions, dim=0)
elif strategy == 'top_k':
# [GOOD Quality] Select k experts most familiar with current image (x_t)
# (In the actual paper, selection is based on cluster distance calculations)
scores = self.calculate_affinity(x_t, self.experts)
top_indices = torch.topk(scores, k).indices
selected_preds = predictions[top_indices]
# Average opinions only from selected 'true experts'
final_pred = torch.mean(selected_preds, dim=0)
return final_pred
def calculate_affinity(self, x, experts):







