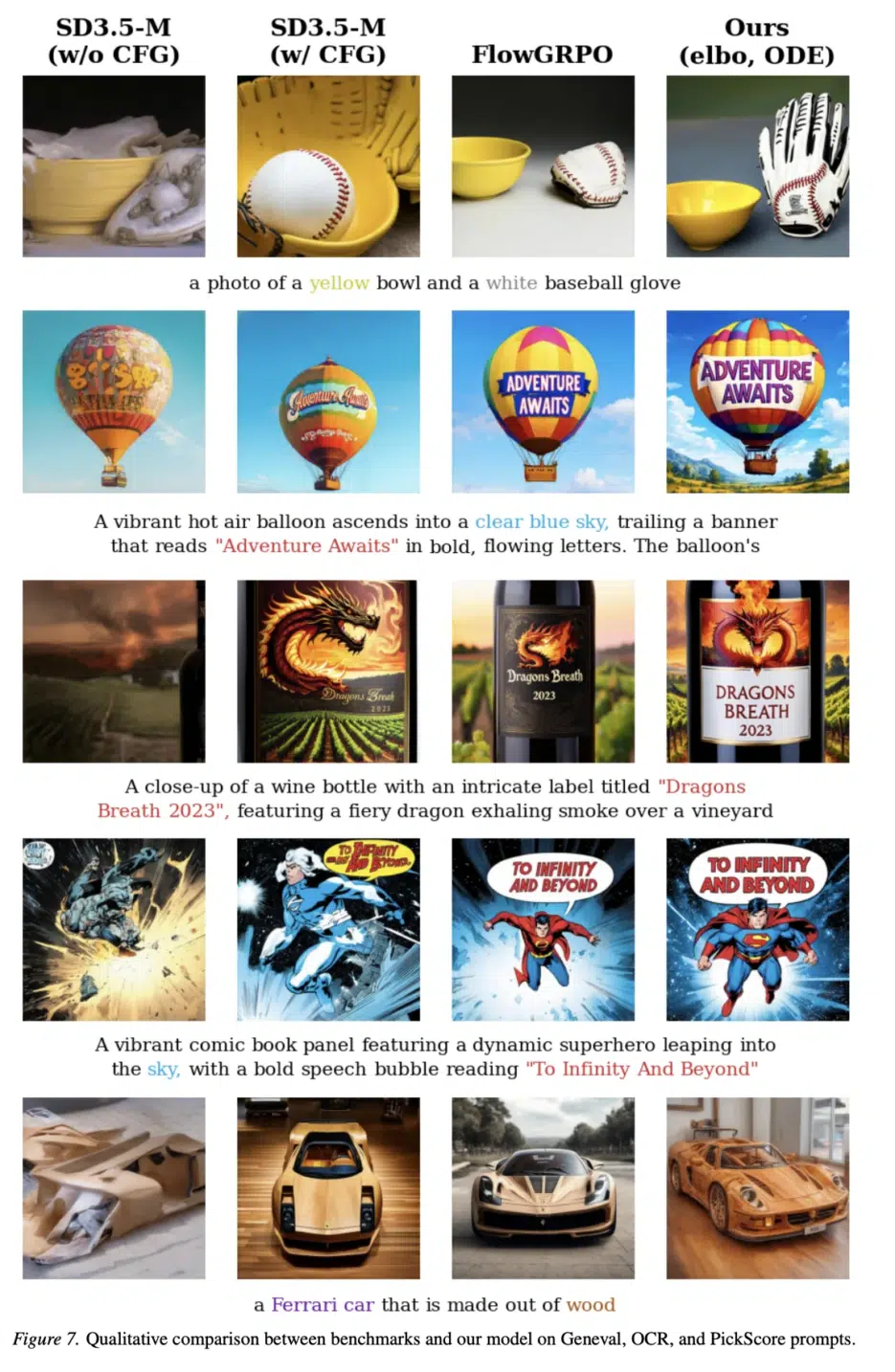
Rethinking the Design Space of Reinforcement Learning for Diffusion Models: On the Importance of Likelihood Estimation Beyond Loss Design - Paper Review
Rethinking the Design Space of Reinforcement Learning for Diffusion Models

Introduction: Why Should We Pay Attention to This Paper Now?
[Editor's Note] With the recent success of DeepSeek-R1, the power of reinforcement learning (RL) in the field of large language models (LLM) has been proven once again. Naturally, AI researchers are turning their attention to the question: "Can we apply this successful formula to image generation AI (Diffusion Models) as well?"
However, attempts so far have not been easy. I myself have experienced training divergence or severe memory shortage when trying to apply algorithms like PPO or GRPO to diffusion models. This is because existing methods were inefficient as they tried to forcibly adapt language model techniques to image models.
The paper I'm introducing today, "Rethinking the Design Space of Reinforcement Learning for Diffusion Models", offers a paradigm-breaking solution at exactly this point. Instead of focusing on the minor concern of "which loss function to use?", the researchers asked the fundamental question: "How should we estimate the model's likelihood?" This approach improved training efficiency by more than 4x. In this article, I will analyze the core findings of this paper and add my perspective on how this will change the AI development landscape going forward.
The Problem with Existing Methods: Too Heavy and Complex
To fine-tune diffusion models with reinforcement learning, you need to know mathematically 'how likely' the model-generated images are (Likelihood).
Representative existing methodologies like FlowGRPO used 'trajectory-based' approaches. To put it simply, it's like recording and calculating every steering angle and speed at every moment while driving to find the optimal route from Seoul to Busan.
Drawback: Since you have to track all intermediate steps, memory consumption is extreme and computational costs are very high.
This inefficiency has been the biggest barrier preventing the commercialization or personalized fine-tuning of diffusion models.
Dissecting the 3 Design Elements of Diffusion RL
To optimize reinforcement learning for diffusion models, the researchers decomposed the entire system into three core components for analysis.
- Policy Gradient Objective: How do we update the model? (e.g., PPO, GRPO, REINFORCE)
- Likelihood Estimator: How do we calculate the probability of generated images? (e.g., Trajectory-based vs ELBO-based)
- Sampling Strategy: How do we generate images? (e.g., Stochastic SDE vs Deterministic ODE)
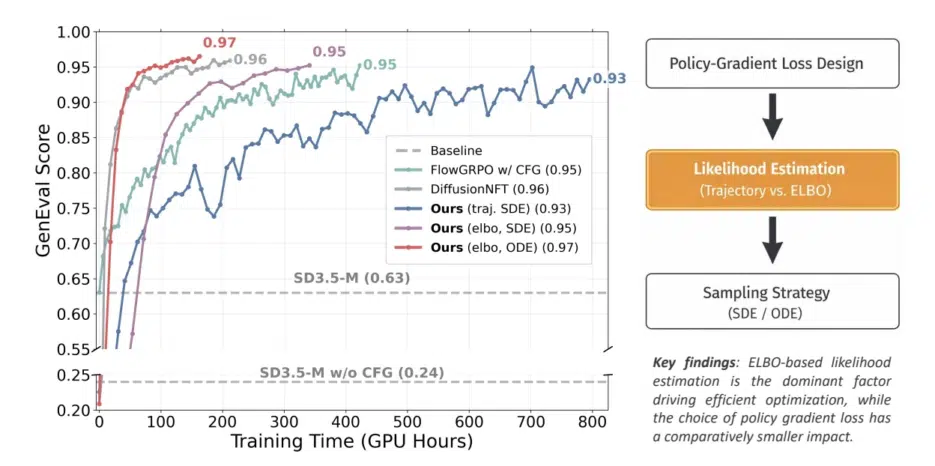
Surprisingly, while people have been obsessed with #1 (objective function), researching PPO clipping techniques and complex normalization tricks, the real 'kingmaker' that determines performance was #2 (likelihood estimator).
Key Finding 1: Abandon Trajectory and Embrace ELBO
The existing trajectory-based approach calculated probabilities by backtracking all intermediate stages of image generation (noisy states).
- Problem: Since all steps must be calculated, it consumes enormous memory. Also, only stochastic SDE (Stochastic Differential Equation) samplers can be used, making computational costs expensive.
In contrast, the ELBO-based approach proposed by the researchers only requires the final generated image.
- Solution: It approximates probability using the Evidence Lower Bound (ELBO). There's no need to track intermediate steps one by one, saving memory, and any sampler (black-box) can be used.
Research results show that using the ELBO method dramatically speeds up training compared to existing methods, and the final performance (GenEval score) is also much higher.
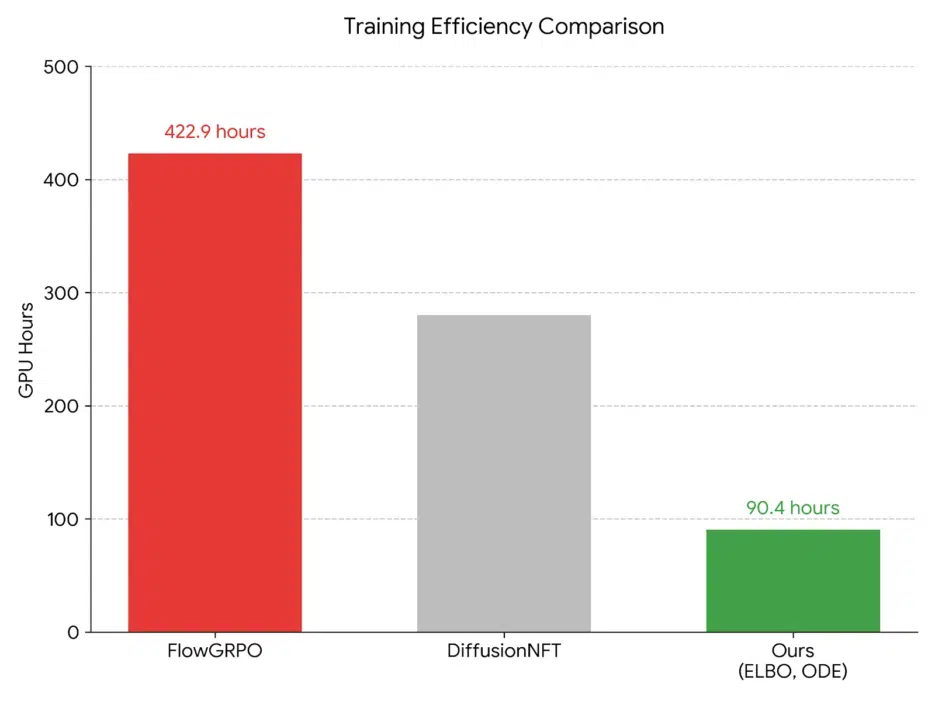
Key Finding 2: Complex Techniques Are Not Necessary (Simple is Best)
It was revealed that techniques considered essential in LLM reinforcement learning, such as Clipping and Advantage Normalization, have little effect in diffusion models.
- Clipping: Used in PPO to prevent the model from changing too drastically, but in diffusion, it either hindered training or had no effect.
- CFG (Classifier-Free Guidance): Normally CFG is enabled during training to produce high-quality images, but the researchers confirmed that turning off CFG during training is faster and solves the train-inference mismatch problem.
In conclusion, the combination of "Accurate probability estimation (ELBO) + Simple loss function (EPG/PEPG) + Fast sampler (ODE)" is the strongest.
Implementation Guide for Developers: ELBO-based RL
Here's a brief Python implementation of the core logic of this paper - ELBO-based probability estimation and update process. Focus on understanding the intuitive flow rather than complex formulas.
import torch
def compute_elbo_likelihood(model, x_0, text_embeddings):
"""
Function to estimate image log likelihood using ELBO
Args:
model: Diffusion model being trained
x_0: Final generated image (Clean Image)
text_embeddings: Prompt embeddings
"""
# 1. Sample random timestep t and noise epsilon
batch_size = x_0.shape[0]
t = torch.rand(batch_size, device=x_0.device) # Time between 0~1
epsilon = torch.randn_like(x_0)
# 2. Generate noisy image x_t at time t (Forward Process)
# alpha_t, sigma_t are obtained from the scheduler
alpha_t, sigma_t = get_noise_schedule(t)
x_t = alpha_t * x_0 + sigma_t * epsilon
# 3. Calculate velocity or noise predicted by the model
pred_velocity = model(x_t, t, encoder_hidden_states=text_embeddings)
# 4. Calculate target velocity (Flow Matching criterion: epsilon - x_0)
target_velocity = epsilon - x_0
# 5. The smaller the prediction error (Loss), the higher the probability.
# ELBO is proportional to the negative of the error.
# w(t) is a weight function (the paper shows setting it to 1 works well)
w_t = 1.0
mse_loss = torch.sum((pred_velocity - target_velocity)**2, dim=[1, 2, 3])
log_likelihood_estimate = -w_t * mse_loss
return log_likelihood_estimate
def train_step(model, old_model, prompt):
# 1. Generate image with old model (Old Policy) using ODE sampler for fast generation
with torch.no_grad():
generated_images = ode_sampler(old_model, prompt, num_steps=10)
rewards = compute_reward(generated_images, prompt)
log_prob_current = compute_elbo_likelihood(model, generated_images, prompt)
torch.no_grad():
log_prob_old = compute_elbo_likelihood(old_model, generated_images, prompt)
ratio = torch.exp(log_prob_current - log_prob_old)
loss = -torch.mean(ratio * rewards)
loss.backward()
optimizer.step()